
The quest for accurate and robust machine learning models is a continuous journey. Choosing the right model and optimizing its performance are crucial steps in this process. This comprehensive guide delves into the world of model selection and boosting in Python, empowering you to navigate the complexities of machine learning with confidence.
Model Selection: Choosing the Right Weapon
What is Model Selection?
Model selection is an essential step in machine learning that involves selecting the most suitable model from a pool of candidates for a specific problem. A well-chosen model generalizes well to unseen data, leading to superior performance on real-world applications. Here’s why it matters:
- Improved Performance: Selecting the right model can significantly impact the accuracy and effectiveness of your machine learning system.
- Reduced Overfitting: Overfitting occurs when a model memorizes the training data too well, leading to poor performance on unseen data. Model selection techniques help mitigate this risk.
- Enhanced Generalizability: The ultimate goal is for a model to perform well on data it hasn’t seen before. Model selection helps identify models that generalize effectively.
Common Model Selection Techniques:
Train-Test Split:
This fundamental technique divides the data into training and testing sets. The model is trained on the training set, and its performance is evaluated on the unseen testing set. This provides a more realistic assessment of how the model will perform on new data.
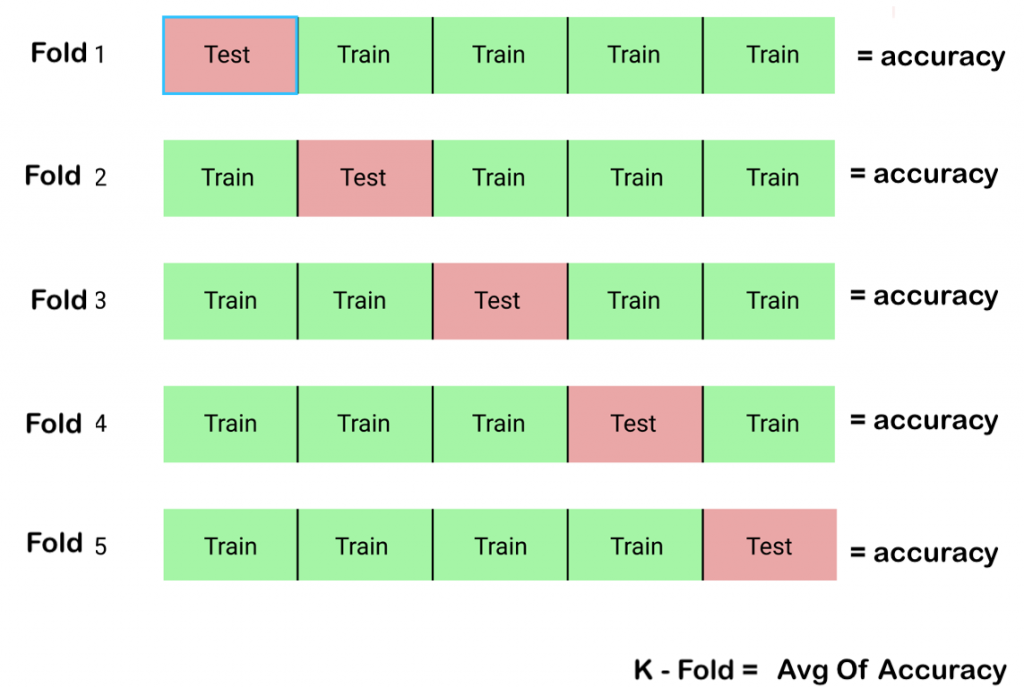
K-Fold Cross-Validation:
This technique splits the data into K folds. In each fold, the model is trained on K-1 folds and evaluated on the remaining fold. This process is repeated K times, providing a more robust estimate of the model’s performance compared to a simple train-test split.
Cross validation is a estimate model prediction using statistical method. In machine learning problem, Have A Two Type OF Data one is training data set and second is testing data set. using Cross validation data scientists check model overfitting or not on testing data predication. variance Reducing in training data set and Bias Reducing in test data set using Cross Validation.
k-fold Cross Validation Is Give K Value for Sampling original data set subsets. each subset known as fold. k-1 rsubsets remaining for training dataset Cross validation. based on k value check cross validation all data set and Estimate accuracy average of k cases Validation.
from sklearn.model_selection import KFold
# prepare cross validation
kfold = KFold(11, True, 1)
# enumerate splits
for train, test in kfold.split(data):
print('train: %s, test: %s' % (data[train], data[test]))
Full Code: Click Hear
Grid Search and Random Search:
These methods explore a predefined space of hyperparameter values (parameters that control the model’s behavior) to find the combination that yields the best performance. Grid search systematically evaluates all combinations, while random search randomly samples from the parameter space.
Grid Search Is Collect data that’s provided in to Grid dictionary and select best parameter them same as trial-and-error method.
from sklearn.model_selection import GridSearchCV
# defining parameter range
param_grid = {'C': [0.1, 1, 10, 100, 1000],
'gamma': [1, 0.1, 0.01, 0.001, 0.0001],
'kernel': ['rbf']}
grid = GridSearchCV(SVC(), param_grid, refit = True, verbose = 3)
# fitting the model for grid search
grid.fit(X_train, y_train)
full code: Click Hear
Evaluation Metrics:
Choosing the right evaluation metric is crucial. For classification problems, metrics like accuracy, precision, recall, and F1-score are commonly used. For regression problems, metrics like mean squared error (MSE) or R-squared are preferred.
Boosting: Combining Weak Learners into a Powerhouse
What is Boosting?
Boosting is a powerful ensemble learning technique that combines multiple “weak learners” (models with relatively low accuracy) into a single “strong learner” (a model with high accuracy). These weak learners are sequentially built, each focusing on improving the errors made by the previous ones. Here’s the core idea:
- Train a weak learner on the original data.
- Identify the data points where the first learner made mistakes.
- Train a second weak learner specifically on those mistakes.
- Combine the predictions of both learners, with more weight given to the learner that performed better on the previously misclassified points.
- Repeat steps 2-4 until a desired level of accuracy is achieved.
Popular Boosting Algorithms:
AdaBoost (Adaptive Boosting):
This is one of the most fundamental boosting algorithms. It assigns weights to data points, increasing the weight of misclassified points in subsequent iterations, forcing the model to focus on those instances.
Gradient Boosting:
This technique uses the gradients of a loss function to guide the learning process. Each weak learner aims to minimize the loss function, leading to a more optimized final model. Common examples include Gradient Boosting Machines (GBMs) and XGBoost.
XGBoost (eXtreme Gradient Boosting)
XGBoost full form is eXtreme Gradient boosting. Make A gradient boosted decision trees. it provide better Speed and performance than GBM(Gradient Boosting). XGboost also handle overfitting and missing values in model.
#XGBRegressor model
import xgboost as xgb
xg_reg = xgb.XGBRegressor(objective ='reg:linear', colsample_bytree = 0.3, learning_rate = 0.1,
max_depth = 5, alpha = 10, n_estimators = 10)
Full Code: Click Hear
LightGBM:
This is a highly efficient implementation of gradient boosting known for its speed and scalability, making it suitable for large datasets.
Advantages of Boosting:
- Improved Performance: Boosting can significantly improve the accuracy and robustness of machine learning models compared to individual weak learners.
- Flexibility: Boosting can be applied to various machine learning algorithms, including decision trees and support vector machines.
- Handles Complex Problems: Boosting can effectively handle complex problems with non-linear relationships between features and the target variable.
However, boosting also comes with some considerations:
- Increased Training Time: Combining multiple models can lead to longer training times compared to single-learner models.
- Overfitting Potential: Boosting algorithms can be prone to overfitting if not carefully tuned.
Putting Theory into Practice: Code Examples in Python
Let’s solidify our understanding with some code examples using popular Python libraries:
1. Train-Test Split with scikit-learn:
from sklearn.model_selection import train_test_split
# Load your data (replace with your actual data)
X = ... # Features
y = ... # Target variable
# Split the data into training and testing sets (test_size=0.2 for 20% test data)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)This code snippet demonstrates splitting data into training and testing sets using train_test_split from scikit-learn. The test_size parameter controls the proportion of data allocated to the testing set (commonly 20-30%). The random_state parameter ensures reproducibility by setting a seed for the random number generator.
2. K-Fold Cross-Validation with scikit-learn:
from sklearn.model_selection import KFold
# Define the number of folds (e.g., 5 folds)
kfold = KFold(n_splits=5, shuffle=True, random_state=42)
# Example model (replace with your actual model)
from sklearn.linear_model import LogisticRegression
# Create an empty list to store model scores
model_scores = []
# Iterate through each fold
for train_index, test_index in kfold.split(X):
# Split data into training and testing sets for the current fold
X_train, X_test = X[train_index], X[test_index]
y_train, y_test = y[train_index], y[test_index]
# Train the model on the training data
model = LogisticRegression()
model.fit(X_train, y_train)
# Evaluate the model on the testing data (e.g., calculate accuracy)
accuracy = model.score(X_test, y_test)
model_scores.append(accuracy)
# Print the average accuracy across all folds
print("Average Accuracy:", np.mean(model_scores))This code example showcases K-Fold cross-validation using KFold from scikit-learn. It defines the number of folds and iterates through each fold, splitting the data and training a model on the training set before evaluating it on the testing set. The code then calculates and prints the average accuracy across all folds, providing a more robust estimate of the model’s performance.
3. AdaBoost with scikit-learn:
from sklearn.ensemble import AdaBoostClassifier
# Define and train the AdaBoost model
model = AdaBoostClassifier(n_estimators=100, random_state=42)
model.fit(X_train, y_train)
# Make predictions on the testing set
y_pred = model.predict(X_test)
# Evaluate the model performance (e.g., calculate F1-score)
from sklearn.metrics import f1_score
f1 = f1_score(y_test, y_pred)
print("F1-score:", f1)This code snippet demonstrates building an AdaBoost model with AdaBoostClassifier from scikit-learn. It specifies the number of estimators (weak learners) to use and sets a random state. The model is trained on the training data, and predictions are made on the testing set. Finally, the code calculates and prints the F1-score to evaluate the model’s performance.
These are just a few examples to illustrate the concepts of model selection and boosting in Python. As you delve deeper, you’ll encounter more advanced techniques and explore various machine learning algorithms.
Considerations and Best Practices
Choosing the Right Approach:
The optimal model selection and boosting techniques depend on your specific problem, data characteristics, and computational resources. Experiment with different approaches and evaluate their performance to find the best fit for your scenario.
Hyperparameter Tuning:
Both model selection and boosting algorithms involve hyperparameters that significantly impact their performance. Techniques like grid search or random search can be use to explore different hyperparameter values and identify the optimal configuration.
What is Parameter Tuning ?
Parameter Tuning is Set Parameter of Internal Model Require when making Model. Parameter Values can be estimate using data.If Parameter Require model to make faster called as parametric model and Not Required Parameter when model building time call as nonparametric. parameters model example: support vectors machine in the define support vectors and linear regression in define coefficients. nonparametric algorithm example: K-nearest neighbour, Decision Trees in this not mandatory.
A hyperparameter is an external parameter value when before model building. hyper parameter is help for make model very fast and better accurate.
Ensemble Learning Powerhouse:
Combining model selection and boosting techniques can be a powerful strategy. For instance, you can use grid search to select the best base learner for boosting or perform K-Fold cross-validation to evaluate the performance of an ensemble model.
Continuous Learning
The field of machine learning is constantly evolving. Stay updated with the latest advancements in model selection and boosting techniques by following research papers, attending conferences, and engaging with the data science community.
Conclusion: Building Robust Machine Learning Systems
By mastering model selection and boosting techniques, you equip yourself with valuable tools to navigate the complex world of machine learning. These strategies empower you to select the most suitable models and optimize their performance, leading to the development of robust and accurate machine learning systems for diverse applications. Remember, the journey doesn’t end here. Keep exploring, experiment, and stay curious to unlock the full potential of machine learning!