
The world of data is brimming with hidden connections and patterns waiting to be discovered. Association rule learning (ARL) emerges as a powerful technique to extract these relationships, particularly in large datasets. This comprehensive guide delves into the fascinating realm of ARL in Python, equipping you to identify intriguing associations within your data and unlock valuable insights.
What is Association Rule Learning?
Association rule learning (ARL) is a technique used to discover frequent itemsets and association rules within transactional data. Imagine a grocery store database that tracks customer purchases. ARL can identify relationships between items, such as “customers who buy bread are also likely to buy butter.” These discovered rules can be valuable for various applications:
- Market Basket Analysis (MBA): In retail, ARL helps identify frequently purchased items together, leading to strategic product placement and targeted promotions.
- Customer Segmentation: Identifying clusters of customers with similar buying patterns can aid in personalized marketing campaigns.
- Fraud Detection: ARL can uncover unusual item co-occurrences that might indicate fraudulent activity.
- Recommendation Systems: Recommending products based on a customer’s past purchases is a common application of ARL.
Understanding the Core Concepts:
- Itemset: A collection of items (e.g., {bread, butter}).
- Support: The proportion of transactions containing the itemset (e.g., if 20% of transactions contain bread and butter, the support is 0.2).
- Confidence: The conditional probability of finding the second item (butter) in a transaction given the presence of the first item (bread).
- Minimum Support: A threshold to filter out infrequent itemsets.
- Minimum Confidence: A threshold to filter out weak association rules.
The ARL Process:
- Data Preparation: Prepare your transactional data, ensuring it’s in a format suitable for ARL algorithms. This often involves one-hot encoding categorical variables.
- Frequent Itemset Generation: Identify itemsets that appear frequently in the data, exceeding the minimum support threshold.
- Association Rule Generation: Generate association rules based on the frequent itemsets. These rules express relationships between itemsets, considering both support and confidence.
- Evaluation and Interpretation: Analyze the generated rules, identify the most interesting ones based on your specific goals, and interpret their meaning in the context of your data.
Python Code Examples for Association Rule Learning
Let’s solidify our understanding with some code examples using popular Python libraries:
1. Frequent Itemset Generation with arules:
from arules import apriori
# Load your transactional data (replace with your actual data)
transactions = [
{'bread', 'butter', 'milk'},
{'bread', 'eggs', 'cereal'},
# ... (more transactions)
]
# Define the minimum support threshold (e.g., 0.2 for 20% of transactions)
min_support = 0.2
# Create an Apriori object
apriori_obj = apriori(transactions, min_support=min_support)
# Generate frequent itemsets
frequent_itemsets = apriori_obj.frequent_itemsets
# Print the frequent itemsets with their support
for itemset in frequent_itemsets:
print(itemset, itemset.support)This code snippet utilizes the arules library to generate frequent itemsets. We define the minimum support threshold and create an Apriori object. The frequent_itemsets attribute stores the discovered frequent itemsets along with their support values.
2. Generating Association Rules with arules:
from arules import apriori
# Load your transactional data (same as previous example)
transactions = ...
# Define minimum support and confidence thresholds
min_support = 0.2
min_confidence = 0.6
# Create an Apriori object
apriori_obj = apriori(transactions, min_support=min_support, min_confidence=min_confidence)
# Generate association rules
association_rules = apriori_obj.association_rules
# Print the association rules with their support and confidence
for rule in association_rules:
print(rule[0], '-->', rule[1], '(support:', rule.support, ', confidence:', rule.confidence, ')')Building upon the previous example, this code demonstrates generating association rules with minimum confidence
This code snippet showcases generating association rules with arules. We define both minimum support and confidence thresholds. The association_rules attribute of the Apriori object stores the discovered rules, along with their support (proportion of transactions containing both the antecedent and consequent) and confidence (conditional probability of the consequent given the antecedent).
3. Visualizing Association Rules with NetworkX (optional):
import networkx as nx
# Load the association rules (replace with your actual rules)
association_rules = ...
# Create a network graph
G = nx.DiGraph()
# Add nodes and edges to the graph
for rule in association_rules:
antecedent = ','.join(rule[0]) # Join items in the antecedent for readability
consequent = ','.join(rule[1])
G.add_edge(antecedent, consequent, weight=rule.confidence)
# Visualize the network graph (using libraries like matplotlib)
import matplotlib.pyplot as plt
nx.draw(G, with_labels=True, font_weight='bold')
plt.show()This optional code demonstrates visualizing association rules as a network graph using NetworkX. We create a directed graph, where nodes represent items and edges represent association rules. The edge weight can be set to the confidence value of the rule. Visualizing the network can help identify clusters of frequently co-occurring items.
4. Exploring Results and Considerations:
Once you have your frequent itemsets and association rules, it’s time to delve into the results and extract valuable insights. Here are some key considerations:
- Rule Filtering and Interpretation: Not all discovered rules are equally valuable. Focus on rules with high support and confidence that align with your specific goals. Consider factors like domain knowledge and business context when interpreting the rules.
- Visualization: Visualizing the relationships between items using techniques like network graphs can aid in understanding the discovered patterns more effectively.
- Data Quality: The quality of your data significantly impacts the effectiveness of ARL. Ensure your data is clean, consistent, and well-formatted for optimal results.
- Advanced Techniques: Libraries like
mlxtendoffer advanced ARL algorithms like FP-Growth, which can be more efficient for dealing with large datasets.
Advanced Techniques and Considerations
Apriori Algorithm:
The Apriori algorithm is a foundational technique for ARL. However, it can be computationally expensive for large datasets. Explore alternative algorithms like FP-growth for improved efficiency.
Three Parameter of Apriori Algorithm is Lift Ratio, support and confidence.
Support measure helps us in filtering out all the possible combination of rules which are exponential. Effect of Antecedent or Consequent being a generalized product cannot be filtered out just by defining Support. Support Calculating As no of item transactions divided by total no of item transactions.

Lift Ratio helps in filtering our Consequents being generalized ones. Lift ratio the increase the sale of Y sell when X is already purchased.
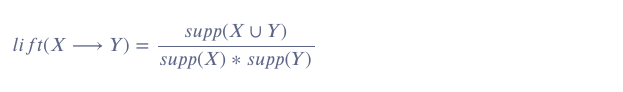
Likelihood is same as Confidence that an item y is buying if item x is already purchased.

Confidence calculate by finding the no of transactions A and B are purchase together divided by total number of purchased transactions A. Confidence helps in filtering out Antecedents being generalized products.Naive Bayes Algorithm as confidence same but both use for different statement.
# import the model apriori and association_rules from mlxtend from mlxtend.frequent_patterns import apriori,association_rules frq_items = apriori(book, min_support = 0.05, use_colnames = True) # Collecting the inferred rules in a dataframe rules = association_rules(frq_items, metric ="lift", min_threshold = 1) rules = rules.sort_values(['confidence', 'lift'], ascending =[False, False]) print(rules.head())
First of all need to pip install pandas. then Read using data pd.read csv file after use pandas dataframe for rule. why we use pandas data frame is quuestion in your mind. answer is in item set, combination of items, customers who buy, total number of transaction data combination for use.
Full Code : Click Here.
Rule Lifting:
While support and confidence are essential, consider rule lifting to identify unexpected relationships. Lifting measures how much more likely the consequent occurs when the antecedent is present compared to its overall occurrence in the data.
Domain Knowledge Integration:
Incorporate domain knowledge into your analysis. For instance, you might filter out nonsensical rules or prioritize rules that align with your business goals.
Evaluating Model Performance:
There’s no single metric for evaluating ARL models. Consider metrics like lift, Matthews correlation coefficient (MCC), or custom metrics based on your specific application.
Applications and Future Directions
Applications of ARL:
Association rule learning empowers you to unlock valuable insights from transactional data. Let’s delve into some key applications:
- Recommendation Systems: ARL can recommend products based on a customer’s past purchases, leading to enhanced user experience and increased sales.
- Fraud Detection: Identifying unusual item co-occurrences can flag potential fraudulent transactions, improving security measures.
- Customer Segmentation: ARL can help group customers with similar buying patterns, enabling targeted marketing campaigns.
- Web Usage Mining: ARL can analyze user website navigation patterns to suggest related content or personalize website layouts.
- Market Basket Analysis (MBA): Identify frequently purchased items together to optimize product placement, cross-promotions, and inventory management.
- Fraud Detection: Identify unusual item co-occurrences that might indicate fraudulent activity, enhancing security measures.
- Clickstream Analysis: Analyze website visitor behavior to understand user journeys and optimize website design and content.
Future Directions in ARL:
- Incorporating Domain Knowledge: Integrating domain knowledge into the ARL process can lead to more meaningful and interpretable rules.
- Handling Complex Data: ARL algorithms are evolving to handle complex data structures beyond simple transactions, including temporal data or hierarchical relationships.
- Scalability and Efficiency: As datasets grow, efficient and scalable algorithms are crucial for practical ARL applications.
Embrace Curiosity and Continuous Learning:
The field of association rule learning is constantly evolving. Explore new algorithms, advanced techniques, and research papers to stay at the forefront of this exciting domain. Utilize online communities and forums to learn from other data scientists and share your discoveries.
Association Rule Algorithm
Eclat Algorithm
Equivalence Class Clustering and bottom-up Lattice Traversal sort form is Eclat. this is one of the best Association Rule technique for medium or small datasets. this algorithm works or only Support Parameter. eclat algorithm mining database vertical manner like as depth first search. Eclat Algorithm faster than Apriori.
#implement apriori from mlxtend.frequent_patterns import apriori,association_rules frequent_itemsets = apriori(df, min_support=0.6, use_colnames=True) (df, min_support=0.6, use_colnames=True) #bulid association rules using support metric rules = association_rules(frequent_itemsets, metric="support", support_only=True, min_threshold=0.1) #use only support metric in Eclat algo using apriori
Full Code: Click Hear
Movies Recommend System algorithm in python using Apriori
# Building the model movie_apiori = apriori(movie, min_support = 0.1, use_colnames = True)
Full Movies Recommend System Code: Click Hear
Conclusion: Unveiling the Secrets Within
Association rule learning in Python equips you with a powerful tool to uncover hidden patterns within transactional data. By harnessing ARL techniques, you can extract valuable insights, make informed decisions, and unlock new possibilities in various applications. Remember, the journey doesn’t end here. Embrace continuous learning, explore advanced techniques, and let ARL guide you towards a deeper understanding of your data.
Thanks very interesting blog!