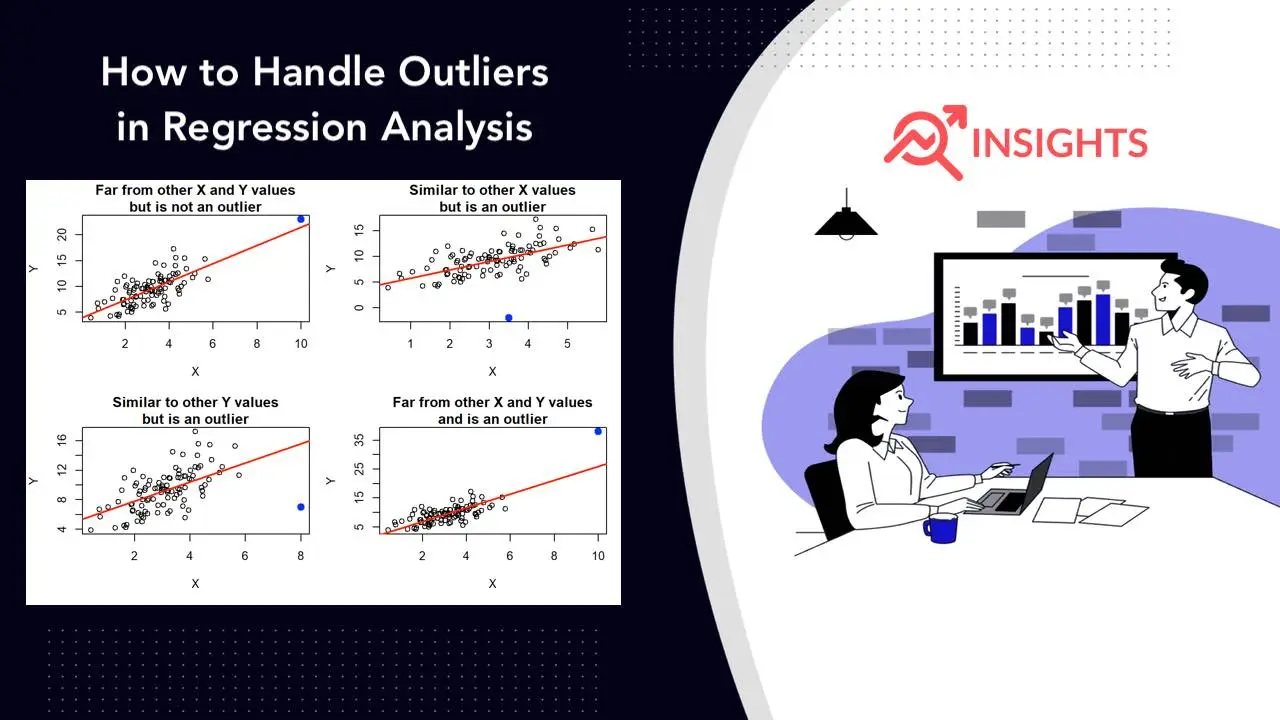
Have you ever wondered why your regression model sometimes gives weird results? The culprit might be outliers – those pesky data points that don’t play by the rules. Outliers can throw off your analysis and lead to incorrect conclusions. But don’t worry! We’ll show you how to spot and deal with these troublemakers in your data.
What Are Outliers?
Outliers are data points that differ significantly from other observations. They can occur due to various reasons:
- Measurement errors
- Data entry mistakes
- Natural variation in the data
- Unusual events or circumstances
Outliers can have a big impact on regression analysis. They can skew results and lead to inaccurate predictions.
Why Do Outliers Matter in Regression?
In regression analysis, outliers can cause several problems:
- They can pull the regression line towards them
- They can increase the error variance
- They can decrease the power of statistical tests
These effects can lead to unreliable models and poor predictions.
Detecting Outliers
Before we can handle outliers, we need to find them. Here are some common methods:
Visual Methods
Visual methods are simple but effective ways to spot outliers:
- Scatter plots
- Box plots
- Histograms
Let’s see how to create these plots using Python:
import matplotlib.pyplot as plt
import seaborn as sns
# Scatter plot
plt.scatter(X, y)
plt.show()
# Box plot
sns.boxplot(x=data)
plt.show()
# Histogram
plt.hist(data, bins=20)
plt.show()
Statistical Methods
Statistical methods provide more rigorous ways to identify outliers:
Z-score
Z-score measures how many standard deviations away a point is from the mean:
from scipy import stats
import numpy as np
z_scores = np.abs(stats.zscore(data))
outliers = np.where(z_scores > 3)
Data points with a z-score greater than 3 are often considered outliers.
Interquartile Range (IQR)
IQR method identifies outliers based on the spread of the middle 50% of the data:
Q1 = np.percentile(data, 25)
Q3 = np.percentile(data, 75)
IQR = Q3 - Q1
lower_bound = Q1 - 1.5 * IQR
upper_bound = Q3 + 1.5 * IQR
outliers = np.where((data < lower_bound) | (data > upper_bound))
Cook’s Distance
Cook’s Distance measures the influence of each data point on the regression results:
from statsmodels.stats.outliers_influence import OLSInfluence
model = sm.OLS(y, X).fit()
influence = OLSInfluence(model)
cooks_d = influence.cooks_distance[0]
Points with Cook’s Distance greater than 4/n (where n is the number of observations) are often considered influential.
Handling Outliers
Once you’ve identified outliers, you need to decide how to handle them. Here are some common approaches:
Remove Outliers
Removing outliers is a simple approach, but use it with caution:
data_clean = data[(z_scores < 3).all(axis=1)]
Only remove outliers if you’re sure they’re due to errors or irrelevant to your analysis.
Transform the Data
Data transformation can reduce the impact of outliers:
data_log = np.log(data)
data_sqrt = np.sqrt(data)
Common transformations include log, square root, and Box-Cox transformations.
Winsorization
Winsorization caps extreme values at a specified percentile:
from scipy.stats.mstats import winsorize
data_winsorized = winsorize(data, limits=[0.05, 0.05])
This example caps values at the 5th and 95th percentiles.
Robust Regression
Robust regression methods are less sensitive to outliers:
from statsmodels.formula.api import rlm
model_robust = rlm("y ~ x", data=df).fit()
This uses Huber’s T norm as a robust regression method.
Use a Different Model
Some models handle outliers better than others. For example, decision trees and random forests are less affected by outliers than linear regression.
from sklearn.ensemble import RandomForestRegressor
rf_model = RandomForestRegressor()
rf_model.fit(X, y)
Evaluating the Impact of Outlier Handling
After handling outliers, it’s important to evaluate the impact on your model:
- Compare model performance before and after handling outliers
- Check if predictions have improved
- Examine residual plots for any remaining issues
from sklearn.metrics import mean_squared_error
mse_before = mean_squared_error(y_test, y_pred_before)
mse_after = mean_squared_error(y_test, y_pred_after)
print(f"MSE before: {mse_before}")
print(f"MSE after: {mse_after}")
Case Study: Housing Price Prediction
Let’s apply these techniques to a real-world example. We’ll use the Boston Housing dataset:
from sklearn.datasets import load_boston
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
boston = load_boston()
X, y = boston.data, boston.target
# Split the data
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# Train a model without handling outliers
model = LinearRegression()
model.fit(X_train, y_train)
y_pred = model.predict(X_test)
mse_before = mean_squared_error(y_test, y_pred)
# Detect outliers using IQR
Q1 = np.percentile(y_train, 25)
Q3 = np.percentile(y_train, 75)
IQR = Q3 - Q1
lower_bound = Q1 - 1.5 * IQR
upper_bound = Q3 + 1.5 * IQR
outliers = np.where((y_train < lower_bound) | (y_train > upper_bound))
# Remove outliers
X_train_clean = np.delete(X_train, outliers, axis=0)
y_train_clean = np.delete(y_train, outliers)
# Train a new model
model_clean = LinearRegression()
model_clean.fit(X_train_clean, y_train_clean)
y_pred_clean = model_clean.predict(X_test)
mse_after = mean_squared_error(y_test, y_pred_clean)
print(f"MSE before handling outliers: {mse_before}")
print(f"MSE after handling outliers: {mse_after}")
This example shows how handling outliers can improve model performance.
Best Practices for Handling Outliers
Here are some tips for dealing with outliers effectively:
- Always visualize your data before analysis
- Use multiple methods to detect outliers
- Understand the context of your data
- Document your outlier handling decisions
- Be cautious about removing data points
- Consider the impact on your sample size
- Use cross-validation to assess the impact of outlier handling
Common Pitfalls to Avoid
When handling outliers, watch out for these common mistakes:
- Blindly removing all outliers without consideration
- Ignoring outliers completely
- Using the same outlier detection threshold for all variables
- Forgetting to check for outliers in the test set
- Not considering the possibility of valid extreme values
Advanced Techniques
For more complex scenarios, consider these advanced techniques:
- Local Outlier Factor (LOF) for multivariate outlier detection
- Isolation Forest for high-dimensional data
- DBSCAN for density-based outlier detection
from sklearn.neighbors import LocalOutlierFactor
lof = LocalOutlierFactor()
outlier_labels = lof.fit_predict(X)
Conclusion
Handling outliers is a critical step in regression analysis. It can significantly improve your model’s performance and reliability. Remember to use a combination of visual and statistical methods to detect outliers. Then, choose an appropriate handling method based on your data and analysis goals.
As you continue to explore regression techniques, you might want to check out our guide on Advanced Regression Techniques in Python. For time-based data, our article on Time Series Regression in Python offers valuable insights. If you’re new to regression, start with our comprehensive guide on Regression in Python. And for a deep dive into regularization methods, don’t miss our article on Ridge and Lasso Regression in Python.