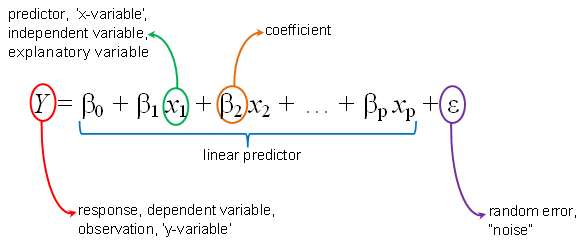
regression analysis stands as a cornerstone technique. It empowers you to uncover the relationship between a continuous dependent variable (what you’re trying to predict) and one or more independent variables (what you’re basing your prediction on). This comprehensive guide delves into the world of regression in Python, equipping you with the knowledge and tools to build robust models and unveil the hidden connections within your data.
What Is Regression?
Regression is statistical processes for find relationship between depends variable and independent variables. depended variable also called as predict or outcome variable. independent variable also call as predictors, covariates, or features variable. independent may be one or more variables.
Regression analysis establishes a mathematical relationship between a continuous dependent variable (often denoted as Y) and one or more independent variables (often denoted as X). This relationship, expressed as an equation, allows you to predict the value of Y for a new set of X values. Here are some common applications of regression:
- Sales Forecasting: Predicting future sales based on factors like marketing spend, economic indicators, and historical data.
- Stock Price Prediction: Estimating future stock prices based on market trends, company performance, and other financial indicators.
- Customer Lifetime Value Analysis: Predicting the total revenue a customer might generate over their relationship with the company, based on past behavior and demographics.
These are just a few examples, and regression finds applications in diverse domains from finance and healthcare to marketing and social sciences.
Regression analysis use for prediction, forecasting and analyse relationship between dependent and independent variable.
Benefits of Regression Analysis:
- Prediction: Regression allows you to predict the value of the dependent variable for new data points based on the learned model.
- Understanding Relationships: By analyzing the model coefficients, you can gain insights into the strength and direction of the relationships between the independent variables and the dependent variable.
- Identifying Influential Variables: Regression can help identify which independent variables have the most significant impact on the dependent variable.
Simple Linear Regression
This fundamental model assumes a linear relationship between the independent variables and the dependent variable. It’s a versatile starting point for many regression tasks.
A model that Predict a linear relationship between the independent variable (x) and the depend (output) variable (y) called as Linear regression or linear model.

#import library
import numpy as np
import pandas as pd
import scipy.stats as stats
from sklearn.linear_model import LinearRegression
import matplotlib.pyplot as plt
#import data set
Emp_data = pd.read_csv("~/Downloads/Data Science/data set/emp_data.csv")
#spilt data set for independent and depend future
x = Emp_data.iloc[:, :-1].values
y = Emp_data.iloc[:,-1:].values
#qq plot
stats.probplot(Emp_data.Churn_out_rate, dist="norm", plot=plt)
plt.title("Normal Q-Q plot")
plt.show()
stats.probplot(Emp_data.Salary_hike, dist="norm", plot=plt)
plt.title("Normal Q-Q plot")
plt.show()
plt.plot(Emp_data.Churn_out_rate,Emp_data.Salary_hike)
plt.show()
#Multicollinearity check
corr = Emp_data.corr()
corr.style.background_gradient(cmap='coolwarm')
#create model
reg = LinearRegression()
#fit model
reg.fit(x,y)
print(reg.score(x, y))
#transform future for better accuracy
reg.fit(np.log(x),y)
print(reg.score(np.log(x), y))
reg.fit(np.log(x),np.log(y))
print(reg.score(np.log(x),np.log(y)))
GitHub Link : Click Hear
Linear Regression Assumptions :
Relationship : A must be linear relationship between independent and predict variables.
No Collinearity : Remove multicollinearity between predictors variables. because model difficult to predict which predictor variable are affect depend variable which not. independent variables depend from each other call multicollinearity
Auto correlations: No Residual Errors Dependent On Each Other. Most Of It is Occur in time series models because where the next instant is dependent on previous instant.
Heteroskedasticity : No Heteroskedasticity, in the scatter plot Should be clear pattern distribution of data called homoscedasticity.
Normal distribution: random variables should be normally distributed. This Is Check using Q-Q Plot.
Multiple Linear Regression
Multiple linear regression is predict relationship between one continuous predict variable and two or more predictors variables. The predictors variables can be continuous or categorical. if categorical then need to convert them dummy variables.
#import libarary
import pandas as pd
import numpy as np
import matplotlib.pyplot as pltfrom
from sklearn.linear_model import LinearRegression
#read csv file
ComputerData = pd.read_csv("~/Downloads/Data Science/data set/Computer_Data.csv")
#Find Correlaton
corr = ComputerData.corr()
corr.style.background_gradient(cmap='coolwarm')
#split data using columan name
x = pd.DataFrame(ComputerData, columns = ['speed', 'hd', 'ram', 'screen', 'ads', 'trend'])
y = pd.DataFrame(ComputerData, columns = ['price'])
# Scatter plot between the variables along with histograms
import seaborn as sns
sns.pairplot(ComputerData)
# Preparing model
reg = LinearRegression()
reg.fit(x,y)
#check score
reg.score(x,y)
GitHub Link : Click Hear
Polynomial Regression
This approach extends linear regression by allowing for non-linear relationships between the independent variables and the dependent variable. It involves transforming the features using polynomial terms.
Polynomial Regression: If (Y)Depened And (X)Indepened variable is correlated but relationship is not liner.
Broad range of function will be fit under it. but too sensitive to the outliers. The presence of one or two outliers within the data can seriously affect the results of the nonlinear analysis.Polynomial basically fits wide selection of curvature.
# Import libraries
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
from sklearn.preprocessing import PolynomialFeatures
from sklearn.linear_model import LinearRegression
# Import the dataset
datas = pd.read_csv('~/Downloads/Data Science/data set/data.csv')
datas
X = pd.DataFrame(datas, columns = ['Temperature'])
y = pd.DataFrame(datas, columns = ['Pressure'])
# Fitting Linear Regression
lin = LinearRegression()
lin.fit(X, y)
# Fitting Polynomial Regression
poly = PolynomialFeatures(degree = 4)
X_poly = poly.fit_transform(X)
poly.fit(X_poly, y)
lin2 = LinearRegression()
lin2.fit(X_poly, y)
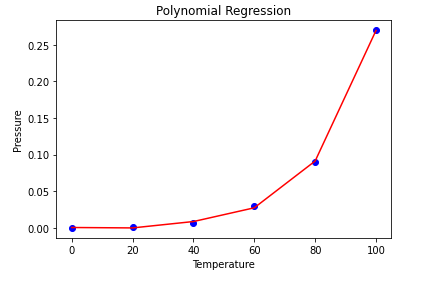
# Visualise Linear Regression results
plt.scatter(X, y, color = 'blue')
plt.plot(X, lin.predict(X), color = 'red')
plt.title('Linear Regression')
plt.xlabel('Temperature')
plt.ylabel('Pressure')
plt.show()
# Visualise Polynomial Regression results
plt.scatter(X, y, color = 'blue')
plt.plot(X, lin2.predict(poly.fit_transform(X)), color = 'red')
plt.title('Polynomial Regression')
plt.xlabel('Temperature')
plt.ylabel('Pressure')
plt.show()
Github link: Click Hear
Support Vector Regression (SVR)
This technique focuses on finding a hyperplane that separates the data points while minimizing the margin of error. It’s robust to outliers and can be effective for high-dimensional data.
Support Vector regression is a part of Support vector machine that supports both linear and non-linear regression.
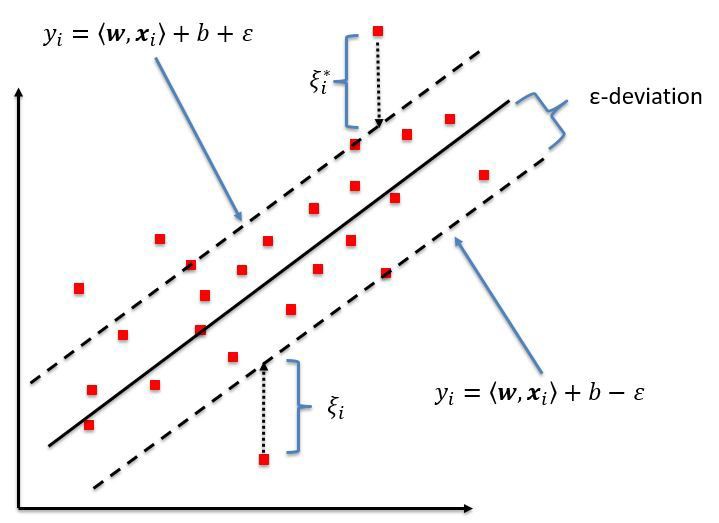
from sklearn.svm import SVR regressor = SVR(kernel = 'rbf') regressor.fit(X, y) #predicte new value y_pred = regressor.predict(6.5) y_pred = sc_y.inverse_transform(y_pred) view raw
Github Link : Click Hear
Decision Tree Regression
This approach builds a tree-like structure to model the relationship between the features and the dependent variable. It’s particularly useful for handling complex non-linear relationships and identifying important feature interactions.
When Out Predicted Variable is continuous (real numbers) then applies Decision Tree Regression

# create a decisiontreeregressor model regressor = DecisionTreeRegressor(random_state = 0) # fit the regressor with X and Y data regressor.fit(X, y)
Github Link : Click Hear
Random Forest Regression
This ensemble method combines multiple decision trees to improve model performance and reduce overfitting. It provides robust predictions for complex regression problems.
A Random Forest is an ensemble technique. opposite to build a single decision tree. random forest build many decision trees. Then combine every decision tree output and give stable output. this technique called Bootstrap Aggregation also known as bagging.
# import the regressor from sklearn.ensemble import RandomForestRegressor # create regressor object regressor = RandomForestRegressor(n_estimators = 100, random_state = 0) # fit the regressor with x and y data regressor.fit(X, y)
Github Code : Click Hear
Best Practices for Effective Regression Analysis in Python
Following these best practices can enhance the effectiveness of your regression analysis in Python:
- Data Preprocessing: Clean, consistent data is crucial for building reliable models. Employ data cleaning techniques like handling missing values and outliers before proceeding with regression analysis.
- Feature Engineering: Crafting informative features from your raw data can significantly improve model performance. Consider techniques like feature scaling, encoding categorical variables, and creating interaction terms.
- Model Selection: Don’t settle for the first model you try. Experiment with different regression techniques and evaluate their performance using techniques like cross-validation.
- Model Evaluation: Assess the performance of your model using metrics like mean squared error (MSE) or R-squared. These metrics help gauge the model’s accuracy in capturing the underlying relationship.
- Model Interpretation: Analyze the model coefficients to understand the impact of each independent variable on the dependent variable. This can provide valuable insights into the data.
Remember, effective regression analysis is an iterative process. Be prepared to experiment, refine your model, and revisit your data preprocessing steps as needed.
Interpreting the Results of Regression
Once you’ve trained your regression model, interpreting the results is crucial to understand the relationship it has captured. Here are some key aspects to consider:
- Model Coefficients: Linear regression, for example, provides coefficients for each independent variable. These coefficients indicate the direction and strength of the relationship between the feature and the dependent variable. A positive coefficient suggests that an increase in the feature value is associated with an increase in the predicted value of the dependent variable. Conversely, a negative coefficient indicates an inverse relationship.
- R-squared: This metric represents the proportion of variance in the dependent variable explained by the model. A higher R-squared value (closer to 1) indicates a better fit, but it’s important to consider it alongside other metrics to avoid overfitting.
- Mean Squared Error (MSE): This metric measures the average squared difference between the predicted values and the actual values of the dependent variable. A lower MSE signifies a better fit.
- Residual Analysis: Plotting the residuals (the difference between actual and predicted values) can reveal potential issues like non-linear relationships or outliers that might impact the model’s performance.
- Beyond these core aspects, consider:
- Model Assumptions: Certain regression models, like linear regression, have underlying assumptions like linearity and homoscedasticity (constant variance of errors). Techniques like diagnostic plots can help assess if these assumptions are met.
- Model Selection: For complex datasets, explore different regression models and compare their performance metrics (e.g., cross-validation) to choose the most suitable model for your task.
- Effective interpretation of regression results empowers you to understand the underlying relationships within your data and evaluate the model’s generalizability.
Applications of Regression in Python
Regression in Python finds applications in diverse domains:
- Business Analytics: Predicting sales, customer churn, and other key business metrics.
- Finance: Modeling stock prices, loan defaults, and risk assessments.
- Marketing: Optimizing advertising campaigns and predicting customer behavior.
- Social Sciences: Analyzing relationships between social and economic factors.
- Science and Engineering: Modeling physical phenomena and predicting outcomes of experiments.
These are just a few examples, and the potential applications of regression in Python extend to various fields where understanding and predicting continuous relationships plays a crucial role.
Conclusion
When Predicted Variable is Should Be Continuous. if not then create dummy variable. in python most of NumPy, scikit-learn, and statsmodels library used.