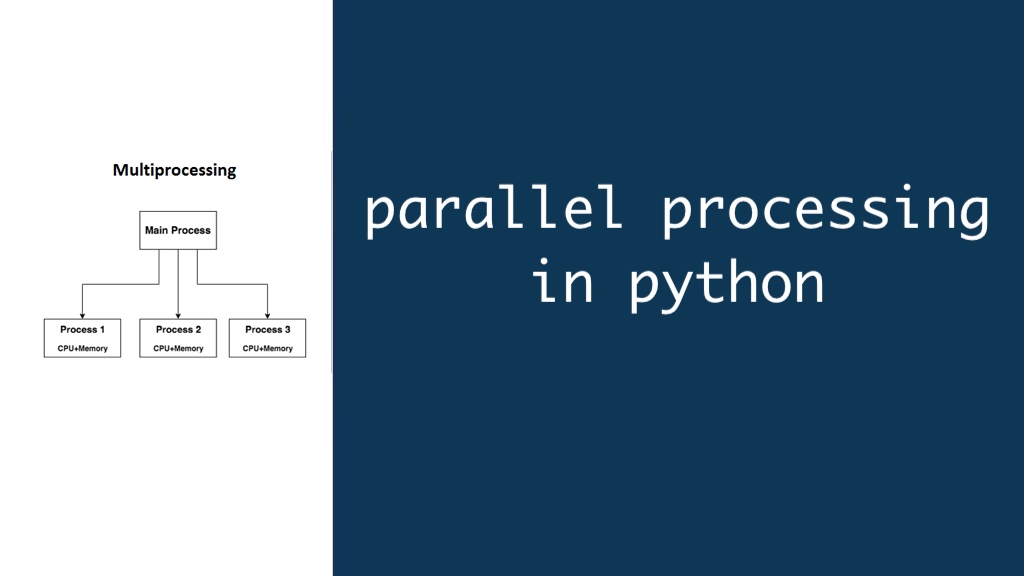
Parallel Processing allows you to make use of the power of modern hardware to process large data sets. The multiprocessing and subprocess modules in Python provide an easy way to explore the capabilities of parallel processing.
data science and computing, harnessing the potential of multiple cores within a computer is paramount. Parallel processing, the art of executing tasks concurrently on multiple processors, offers a compelling solution to accelerate computationally intensive tasks. This comprehensive guide delves into the world of parallel processing in Python, empowering you to unlock the hidden processing power within your machine.
What is Sequential vs. Parallel Processing
Before diving into parallel processing techniques, let’s establish a clear distinction between sequential and parallel processing:
- Sequential Processing: This traditional approach executes tasks one after another. Imagine a single chef meticulously preparing a dish, each step following the previous in a linear fashion. While efficient for simpler tasks, sequential processing struggles with computationally intensive workloads.
- Parallel Processing: Here, the workload is divided into smaller, independent tasks that can be executed simultaneously on multiple processors. Think of a bustling kitchen with multiple chefs working on different components of a meal concurrently, significantly accelerating the overall preparation time.
Embracing Concurrency: The Multiprocessing Module
Python offers a built-in library, multiprocessing, that provides functionalities for creating processes – independent units of execution that can leverage multiple cores. The multiprocessing module allows you to:
- Spawn Processes: Create multiple processes that run in parallel, each with its own Python interpreter and memory space. This is ideal for computationally intensive tasks that don’t require frequent communication between processes.
- Utilize Process Pools: Manage a pool of worker processes that can be assigned tasks dynamically. This approach is efficient for handling multiple independent tasks with varying execution times.
Key Considerations When Choosing an Approach:
The optimal choice between multiprocessing and threading depends on several factors:
- The Global Interpreter Lock (GIL): Python’s GIL restricts only one thread to execute Python bytecode at a time, even with multiple threads. This can limit the effectiveness of threading for CPU-bound tasks.
- Nature of the task: CPU-bound tasks benefit more from multiprocessing, while I/O-bound tasks are better suited for threading.
- Communication needs: If subtasks require frequent communication, multiprocessing might introduce overhead due to inter-process communication mechanism
Illustrative Example: Factorial Calculation (Sequential vs. Parallel)
Let’s explore the power of parallel processing with a simple example: calculating factorials. Here’s a sequential implementation:
def factorial_sequential(n):
if n == 0:
return 1
else:
return n * factorial_sequential(n-1)
# Calculate factorial of 10 (can be time-consuming for larger numbers)
result = factorial_sequential(10)
print(result)This code calculates the factorial recursively, leading to sequential execution. Now, let’s see how we can parallelize this task using the multiprocessing module:
from multiprocessing import Pool
def factorial_parallel(n):
if n == 0:
return 1
else:
return n * factorial_parallel(n-1)
# Calculate factorials of multiple numbers (10, 12, 14) concurrently
with Pool(processes=4) # Create a pool with 4 worker processes
results = pool.map(factorial_parallel, [10, 12, 14])
print(results) # Output: [3628800, 479001600, 87178291200]This example utilizes a process pool with four worker processes. Each process calculates the factorial for a specific number concurrently, significantly reducing the overall execution time compared to the sequential approach.
Exploring Threading with the threading Module
While multiprocessing excels at tasks with minimal communication between processes, Python also offers the threading module for another form of parallel processing – threading. Threads are lightweight units of execution within a single process that share memory space. This makes them ideal for tasks requiring frequent communication or data sharing:
- Concurrent I/O Operations: Threading shines in handling tasks like network requests or file I/O, where waiting for one operation doesn’t necessarily block others.
- Interactive Applications: Threading allows for a more responsive user experience in applications by handling user interactions and background tasks concurrently.
Illustrative Example: Downloading Files (Sequential vs. Threaded)
Here’s an example of downloading multiple files sequentially:
import requests
def download_file_sequential(url, filename):
response = requests.get(url)
with open(filename, 'wb') as f:
f.write(response.content)
# Download 3 files sequentially (can be slow)
download_file_sequential('url1', 'file1.txt')
download_file_sequential('url2', 'file2.txt')
download_file_sequential('url3', 'file3.txt')Now, let’s see how threading can accelerate this process:
from threading import Thread
def download_file_threaded(url, filename):
response = requests.get(url)
with open(filename, 'wb') as f:
f.write(response.content)
# Download 3 files concurrently using threads
threads = []
for url, filename in [('url1', 'file1.txt'), ('url2', 'file2.txt'), ('url3', 'file3.txt')]:
thread = Thread(target=download_file_threaded, args=(url, filename))
threads.append(thread)
thread.start()
# Wait for all threads to finish
for thread in threads:
thread.join()
print('All files downloaded!')Choosing the Right Tool for the Job: Threading vs. Multiprocessing
The choice between threading and multiprocessing hinges on the nature of your tasks:
- CPU-bound tasks: If your tasks are computationally intensive and don’t require frequent communication (e.g., large calculations, simulations), multiprocessing is generally a better choice. It leverages multiple cores effectively, leading to faster execution.
- I/O-bound tasks: For tasks involving frequent I/O operations (e.g., network requests, file I/O) where execution might be blocked waiting for external resources, threading can be advantageous. Threads can handle waiting periods more efficiently since they don’t incur the overhead of creating and managing separate processes.
- Communication Considerations: If your tasks necessitate frequent communication or data sharing between subtasks, threading might be more suitable due to the shared memory space within a process. However, excessive communication between threads can introduce overhead and negate performance gains.
The Global Interpreter Lock (GIL) and its Implications
It’s crucial to understand the concept of the Global Interpreter Lock (GIL) within the Python interpreter. The GIL ensures only one thread can execute Python bytecode at a time. While this safeguards data integrity in single-threaded applications, it can limit the potential speedup achievable with threading in CPU-bound tasks.
For scenarios where full utilization of all CPU cores is paramount, consider alternative libraries like concurrent.futures or explore languages like C++ or Java that don’t have a GIL.
Advanced Techniques for Parallel Processing
The Python ecosystem offers an array of advanced libraries and frameworks that cater to specific parallel processing needs:
- Joblib: Streamlines parallel processing tasks by providing a high-level interface for running functions on multiple cores or clusters.
- Dask: A powerful framework for parallel computing in Python, enabling scaling to large clusters or cloud environments.
- Ray: Another versatile framework offering distributed task execution with support for fault tolerance and scalability.
- NumPy and SciPy: These libraries provide functionalities for vectorized operations, leveraging multiple cores for efficient numerical computations.
Exploring Joblib for Parallel Function Execution:
Here’s an example utilizing Joblib to parallelize a simple function:
from joblib import Parallel, delayed
def compute_something(x):
# Simulate some computation
return x**2
# Run the computation on 4 cores in parallel
results = Parallel(n_jobs=4)(delayed(compute_something)(i) for i in range(10))
print(results)Joblib facilitates parallelizing the compute_something function across four cores, showcasing its ability to streamline parallel function execution.
Optimizing Parallel Processing for Peak Performance
Here are some key considerations to optimize your parallel processing code:
- Granularity of tasks: Ensure your tasks are sufficiently granular to avoid overhead associated with creating and managing processes or threads. Aim for tasks that take a reasonable amount of time to execute.
- Load balancing: Strive to distribute the workload evenly among available processors to maximize resource utilization.
- Communication overhead: Minimize communication between processes or threads if possible, as frequent data exchange can become a bottleneck.
- Profiling: Utilize profiling tools to identify bottlenecks and optimize code for parallel execution.
Parallel Processing for Real-World Applications
Parallel processing unlocks a vast array of possibilities in various domains:
- Machine Learning: Parallelizing training algorithms on large datasets significantly accelerates model training times.
- Data Science: Executing data cleaning, transformation, and analysis tasks in parallel can dramatically reduce processing times for big data.
- Scientific Computing: Parallelizing scientific simulations and calculations can lead to faster results and enhanced problem-solving capabilities.
- Financial Modeling: Simulating complex financial models and risk analyses benefit from parallelization, leading to faster insights.
Conclusion: Unlocking the Power of Parallelism
Mastering the art of parallel processing in Python empowers you to tackle computationally intensive tasks with remarkable efficiency. By harnessing the combined processing power of multiple cores, you can significantly reduce execution times, accelerate data analysis workflows, and unlock the full potential of your Python code.
Remember, the choice of technique (multiprocessing, threading, or advanced libraries) depends on the nature of your tasks. Experiment, evaluate, and leverage the most suitable approach to propel your Python projects to new heights of performance!